Harness Engineering-耗时一周AI Coding率提升至90
Harness Engineering:耗时一周,AI Coding率从25%提升至90%
核心观点
本文是目前最完整的 Harness Engineering 企业级落地实战文章。作者在一个真实的10万+行Java应用(Spring Boot / LiteFlow / HSF / Diamond / Tair)中,从零构建完整 Harness 体系,耗时一周,将AI代码率从24.86%提升至90.54%。文章系统覆盖了理论基础(Anthropic四种失败模式、OpenAI百万行代码经验)和实操细节(四要素架构、十阶段流水线、九个Skill、变更管理),是"从概念到工程化落地"的标杆参考。
"Agents aren't hard; the Harness is hard." — Ryan Lopopolo, OpenAI
三次范式跃迁
| 阶段 | 时间 | 核心隐喻 | 关注点 |
|---|---|---|---|
| Prompt Engineering | 2022-2024 | 写好一封邮件 | 单次交互优化 |
| Context Engineering | 2025 | 附上正确附件 | 动态上下文窗口内容 |
| Harness Engineering | 2026 | 设计完整控制系统 | 跨会话、多Agent角色、多阶段系统架构 |
Mitchell Hashimoto 的操作性定义:
"Every time you discover an agent has made a mistake, you take the time to engineer a solution so that it can never make that mistake again."
Agent四种典型失败模式(Anthropic总结)
- One-shot Syndrome:试图一步到位,上下文消耗过半后出现幻觉/循环输出。Sweet Spot: 上下文填充率 ≤40%
- Premature Victory Declaration:部分完成就宣布结束,核心功能未实现或验证
- Premature Feature Completion:认为功能已实现但未做端到端测试,部署后关键路径不通
- Cold Start Problem:多会话间无持久化记忆,每次重新理解项目结构挤压编码Token Budget
共同根源:Agent缺乏外部结构化约束和反馈机制。Agent根本性缺陷——"Agents are incapable of accurately evaluating their own work"。
四根支柱
- 上下文架构(Context Architecture):AGENTS.md控制在~100行作为Index & Map,指向Design Docs/Architecture Specs/Quality Criteria。上下文分层加载按需获取
- Agent专业化(Agent Specialization):受限工具集的专业Agent优于全权限通用Agent。Planner/Generator/Evaluator分离——"将做事的Agent和评判的Agent分开是强力杠杆"
- 持久化记忆(Persistent Memory):进度持久化在文件系统(progress.md),非上下文窗口。标准启动序列:检查目录→读Git Log→定位最高优先级未完成任务→开始
- 结构化执行(Structured Execution):理解→规划→执行→验证,Custom Linter + Structure Tests + Taste Invariants 机械化约束替代文档层面"建议"
企业级实战:四要素架构
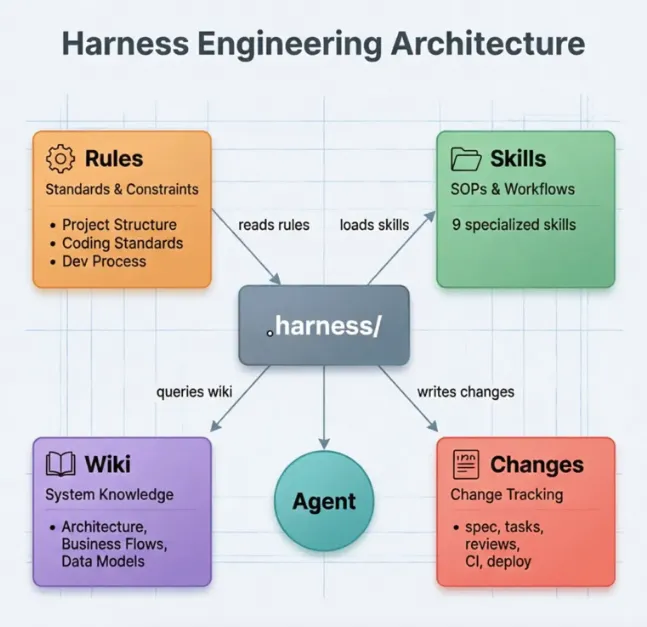
四要素:
- 规则体系(Rules):不随需求变化的稳定约束(Invariant Constraints)
- 技能体系(Skills):可复用标准化工作流程(Reusable Workflows)
- 知识库(Wiki):Agent理解业务上下文的素材(Domain Context)
- 变更管理(Changes):完整追溯链(Audit Trail)
Application Owner Agent
整套体系的编排中枢,~400行定义文件,五个核心模块:
- 角色与项目背景:20-30行,身份定位+核心背景
- 配置中枢索引:结构化表格列出Rules/Skills/Wiki/MCP路径、职责、触发场景
- 七项核心职责:需求理解/任务拆解/任务分发/任务验收/质量把关/文档维护/知识问答
- 工作流程调度指令:10阶段每阶段的完整调度逻辑
- 沟通原则与硬性约束:必须做到/禁止做的两张清单
上下文分层加载
| 层级 | 名称 | 内容 | 策略 |
|---|---|---|---|
| L1 | 会话常驻层 | Agent定义+3份Rules | Always Loaded,总量<40% |
| L2 | 阶段触发层 | 对应阶段Skill+编码Spec | Phase-triggered |
| L3 | 按需查询层 | Wiki业务文档 | On-demand |
十阶段开发流程
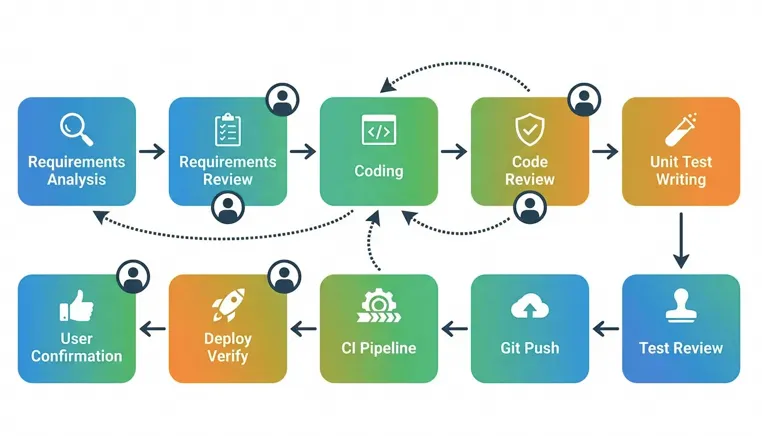
关键设计:
- 每阶段三要素:触发条件 / Skill加载 / 质量门禁
- 回退路径:CI失败→测试编写;编译错误→编码实现;需求不符→需求分析
- 循环上限:需求评审3轮、编码/测试评审2轮,超出升级人工
- 5个Human-in-the-Loop确认点:需求待决议/计划评审/编码评审/部署参数/最终交付
Skill体系:隐性知识显性化
以coding-skill为例,含8份分层编码规范:
| 层级 | 核心内容 |
|---|---|
| 表现层 Controller | RPC Provider模式/参数校验/异常处理 |
| 应用层 接口定义 | RPC接口规范/DTO设计原则 |
| 业务层 逻辑 | 核心逻辑封装/流程编排组件写法 |
| 数据层 持久化 | DDL规范/Mapper编写 |
| 适配层 依赖 | 外部RPC超时/降级 |
| 文档层 | 对外接口协议模板 |
硬性约束示例:
- 价格字段必须用
long类型(单位为分),禁止double/float - 外部服务调用必须设超时和降级
- 流程编排组件必须委托Service,组件内不写大段逻辑
expert-reviewer定义两种评审循环(计划评审/执行评审),每条意见含:问题描述+修改建议+优先级(MUST FIX / LOW / INFO)。
unit-test-write采用"改动驱动测试"原则:改哪个接口测哪个接口,优先通过MCP查询被改接口的线上真实请求出入参构造测试数据。
变更管理
评审文件版本递增永不删除,确保完整Audit Trail。
关键经验
1. Harness需要Dry Run
空跑发现四个缺陷:CI门禁忽略测试用例数为0、评审报告简单需求下不生成、摘要文件重复行、部署参数被Agent错误推测。
2. 质量门禁必须可程序化验证
"If it can't be mechanically enforced, the agent will drift."
"检查CI是否通过"不够→改为 status == SUCCESS && total_tests > 0 && passed == total。一切不可被机器验证的约束在Agent执行中都是无效约束。
3. 分离执行与评判
评审Agent发现了编码Agent遗漏的渠道判断逻辑(潜在线上故障),还检测到Agent试图跳过评审阶段并强制回退。
4. 流程一致性优先于效率
2文件6行代码的小需求也走完10阶段——好流程不给简单任务增加显著负担。
5. 规范是活文档
"规范的每一行都对应一个历史失败案例。"
效果数据
| 时期 | AI采纳行数 | 提交行数 | AI占比 |
|---|---|---|---|
| 3月基线(无Harness) | 1,411 | 5,676 | 24.86% |
| 4月(Harness成熟) | 3,063 | 3,383 | 90.54% |
个人维度从14.24%跃升至87.85%。涵盖新增过滤规则、接口字段扩展等多种变更类型,代表常态化产出。
更深层收益:返工从3-5轮降至Agent-to-Agent内部完成质量纠偏后人工1轮确认。.harness/目录构成活的"项目开发手册",新人和Agent通过相同阅读路径快速理解全貌。
未来方向
- Harness自我进化(Agent自动分析历史失败提出规范改进)
- 跨项目Harness模板化
- 更精细Agent角色矩阵(Performance Auditor / Security Scanner / Documentation Sync Agent)
- 存量代码库渐进式引入
关键引用
"模型的原始能力已经足够强,但从'能力'到'可信赖的工程产出'之间,还横亘着一道系统性鸿沟。"
"未来的工程竞争力将不再取决于谁的Prompt写得更好,而是取决于谁的Harness设计得更精密、更可靠、更具可演化性。"
"开发者核心竞争力正从'写代码'转向'设计Agent的工作环境'。"